Processes
Deploying a template
The process described below is true for all templates with the exception of AWS Environment.
When a user selects a template in the catalog and clicks Create, the below process is initiated.
- Template Creation: The process of filling the template with the required input from the user, text fields, selecting other entities, choosing options etc.
- Rendered Entity Data: Based on the previous selection, this process will fetch all the required data before populating the repository. This includes information about the selected environment entity, platform configurations and entity rendered data. You can see the result of this process in the generated repository right after creation. This process make use of the Scaffolder actions plugin.
- Create Repository: Create the git repository for the entity, code, IaC and environment information. Based on the type of template, the repository will be created in a git project group: environments, environment-providers, aws-app, aws-resources. This allows us to segregate access control from managing repositories under different security domains.
- Store initial files and pipeline: Persisting the generated files from step 2 in the repository including the particular pipeline pattern that fits the selected template (See below for more details on pipeline process).
- Pipeline execution: Using Gitlab runner executing the pipeline in a separate shell. For building container images, we use Docker in Docker with Paketo build packs or Kaniko
- Get Credentials: Fetch credentials from the target (Environment provider) provisioning role in order to provision the IAC for the template.
- Provision IaC: Provision the IaC against the target destination (Environment provider) - cdk deploy / terraform apply
- Update Entity catalog: Based on step 7 select the desired IaC deployment output and update the entity catalog file (catalog-info.yaml) with the resources information.
Executing Gitlab pipeline
The pipeline execution process is composed of several patterns and abstractions. This was done for several reasons, but mostly for reusability and security controls.
Abstracted centralized pipelines
In order to allow updates and changes for pipelines that may be enforced by the platform engineering team, we externalized some of the pipeline actions and provide only the necessary variables as an input.
stages:
- env-creation
- prepare-dev-stage
- dev-stage
variables:
APP_SHORT_NAME: "my-app"
APP_TEMPLATE_NAME: "example-nodejs"
OPA_PLATFORM_REGION: "us-east-1"
include:
- project: 'opa-admin/backstage-reference'
ref: main
file:
- 'common/cicd/.gitlab-ci-job-defaults-cdk.yml'
- 'common/cicd/.gitlab-ci-aws-base.yml'
- 'common/cicd/.gitlab-ci-aws-iac-ecs.yml'
- 'common/cicd/.gitlab-ci-aws-image-kaniko.yml'
The first part of our pipeline, "stages", defines the stages of this pipeline for the current state. This part is not fixed, we may introduce more stages when our application will be deployed to additional environments. Nonetheless we can see the first two stages for our dev environment:
- prepare-dev-stage - this stage provisions and prepares the environment to be able to run the application before we start making continuous code changes to our repositories.
- dev-stage - this stage is responsible for compiling, building and deploying new versions of our application each time we push new code changes to our application logic (/src directory)
The env-creation is the stage to create the two stages above, the reason this is a stage on it's own is because we can reuse it to create more stages later, when the application is deployed to other environments.
The include clause allows us to dynamically pull pipelines from another repository each time the pipeline will run.
Modular pipelines
The idea of modular pipelines is to include smaller pipelines that contain jobs which together can provide a building block for different pipeline orchestrations. You may have already noticed from the example above we use several include statements. These statements help to reuse similar functionally for different templates / application patterns.
The complete list of pipeline patterns is available at: CICD Directory
- .gitlab-ci-aws-base.yml
- .gitlab-ci-aws-dind-spring-boot.yml
- .gitlab-ci-aws-iac-ecs.yml
- .gitlab-ci-aws-iac-rds.yml
- .gitlab-ci-aws-iac-serverless-api.yml
- .gitlab-ci-aws-iac-tf-ecs.yml
- .gitlab-ci-aws-image-kaniko.yml
- .gitlab-ci-aws-provider-ecs.yml
- .gitlab-ci-aws-provider-serverless.yml
- .gitlab-ci-aws-tf-base.yml
- .gitlab-ci-job-defaults-cdk.yml
- .gitlab-ci-job-defaults-tf.yml
Pipeline jobs
There are several jobs imported into the pipeline based on the pattern you use. Below is an example of pipeline executions and the job for each one of them:
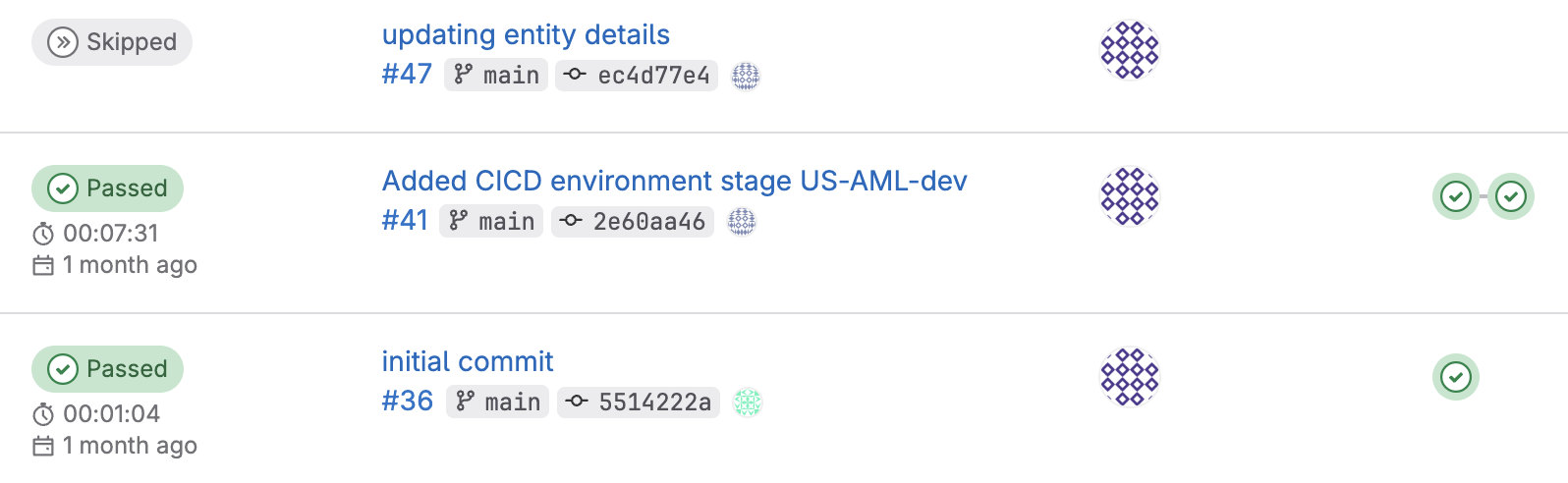
- Initial commit
- create-ci-stages - The job creates new stages for a target environment with its providers.
- Added CICD environment stage
- iac-deployment-ENVXXX-ProviderYYY - the job provision IAC against the target environment/provider
- get-aws-creds-ENVXXX-ProviderYYY - the job gets credentials from the provisioning role of the target provider
- build-image-ENVXXX-ProviderYYY - the job build a new image from the /src directory and update the container image
- delete-aws-creds-ENVXXX-ProviderYYY - delete the temporary credentials so that they are not persisted in the repository
- updating entity details - update cataloginfo.yaml with the IaC metadata. There is no need to run the pipeline again after this update, which is why the pipeline is showing as "Skipped".
Deploy an application to another environment
The process of deploying an application to another environment works by utilizing the jobs and stage we describe above. To visualize how the git pipeline looks when performing a multi-environment deployment, let's look at the below diagram.
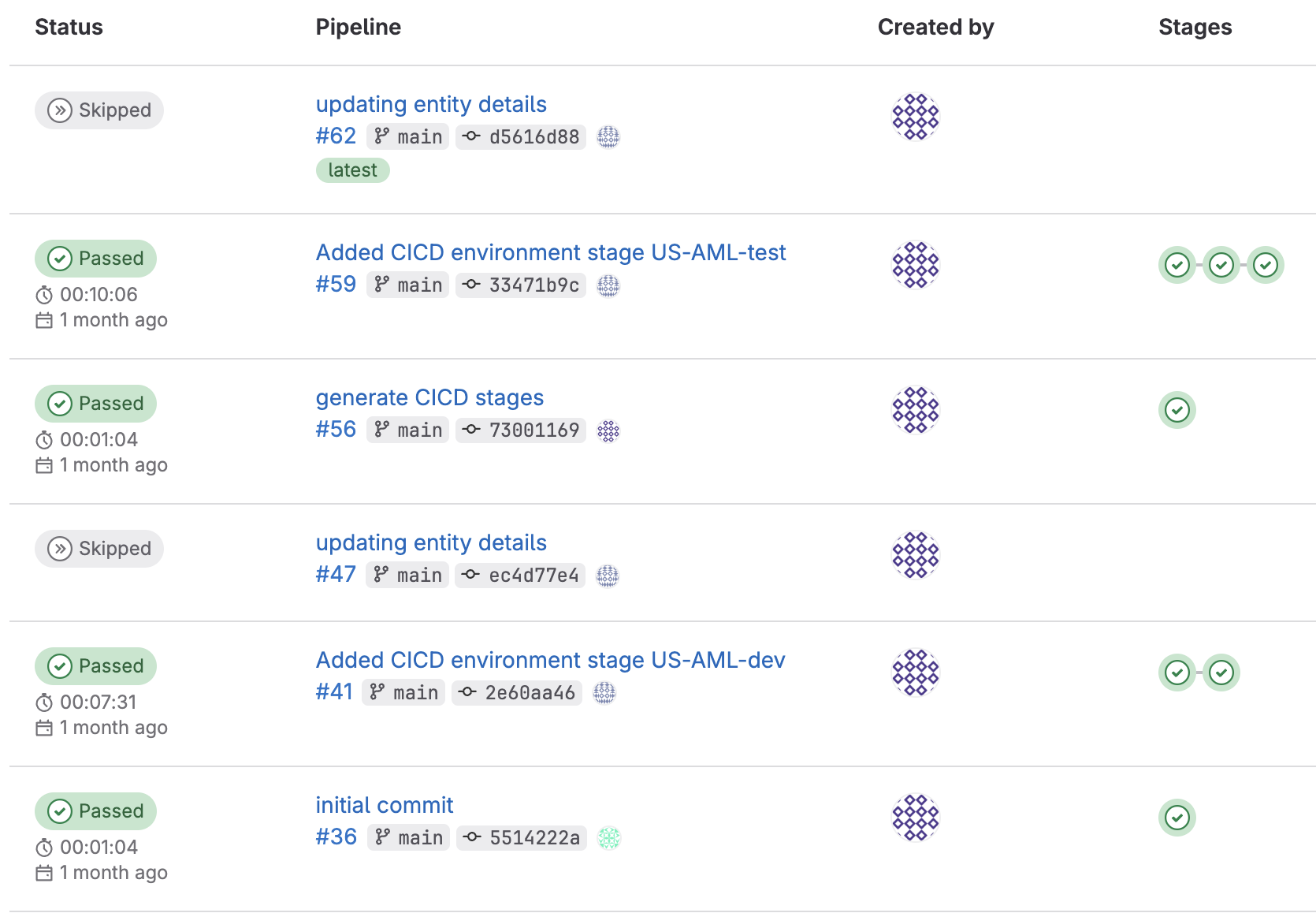
We can see that once we deploy an application to another environment we essentially created new stages for the new target environment.
The process to deploy an application to another environment is done by submitting a commit to git with a specific message generate CICD stages along with a properties file that contains the information of the new target environment. When the pipeline job runs, it will process the new file and create corresponding stages for the new target destination. This change will automatically execute the pipeline and stage to deploy the application to the new target environment.
Continuous deployment for app code
How do the application logic code changes propagate to multiple environments? For example - if we have the below pattern of commit on our repository - every time we merge changes to the main branch /src directory (Can be configured differently) the ENV-XXX-stage will be triggered.
If we have several stages for multiple environments, all of them will be triggered in the original order they were created in.
If we configured the environment with "Requires approval", the pipeline that pushes code changes will halt until an approval is granted. This is useful in cases where we want supervision of what changes are propagated to a sensitive environment. Additional security controls can also be implemented.